Hi Guys today i am coming to write in very interesting subject for any DBA and DB analyst , any DBA should be care from more things one of this is Database design for this database design we should take care from heap tables and this one of the steps of Database assessment to check all heap tables and fix them by creating new Clustered index.
Hi Guys today i am coming to write in very interesting subject for any DBA and DB analyst , any DBA should be care from more things one of this is Database design for this database design we should take care from heap tables and this one of the steps of Database assessment to check all heap tables and fix them by creating new Clustered index.
based on that i write one script to return the tables with more information then i will filtered it to return only the tables without any index then i will loop on this amount of tables to create dynamic statement for Create cluster index for each table.
— =============================================
— Author: Mustafa EL-masry
— Create date: 01/03/2015
— Description: DMV Create Clustered index on all heap tables by on single click
— =============================================
SET NOCOUNT ON
CREATE TABLE #Table_Policy
(
ID INT PRIMARY KEY
IDENTITY(1, 1)
NOT NULL ,
Table_Name NVARCHAR(100) ,
Rows_Count INT ,
Is_Heap INT ,
Is_Clustered INT ,
num_Of_nonClustered INT
);
WITH cte
AS ( SELECT table_name = o.name ,
o.[object_id] ,
i.index_id ,
i.type ,
i.type_desc
FROM sys.indexes i
INNER JOIN sys.objects o ON i.[object_id] = o.[object_id]
WHERE o.type IN ( ‘U’ )
AND o.is_ms_shipped = 0
AND i.is_disabled = 0
AND i.is_hypothetical = 0
AND i.type <= 2
),
cte2
AS ( SELECT *
FROM cte c PIVOT
( COUNT(type) FOR type_desc IN ( [HEAP], [CLUSTERED], [NONCLUSTERED] ) ) pv
)
INSERT INTO #Table_Policy
( Table_Name ,
Rows_Count ,
Is_Heap ,
Is_Clustered ,
num_Of_nonClustered
)
SELECT c2.table_name ,
[rows] = MAX(p.rows) ,
is_heap = SUM([HEAP]) ,
is_clustered = SUM([CLUSTERED]) ,
num_of_nonclustered = SUM([NONCLUSTERED])
FROM cte2 c2
INNER JOIN sys.partitions p ON c2.[object_id] = p.[object_id]
AND c2.index_id = p.index_id
GROUP BY table_name
————————————————————————————–
–DMV
————————————————————————————–
—-Tables didn’t have Primary key and didn’t have any index
SELECT *
FROM #Table_Policy
WHERE num_Of_nonClustered = 0
AND Is_Heap = 1
DECLARE @name NVARCHAR(100)
DECLARE db_cursor CURSOR
FOR
SELECT Table_Name
FROM #Table_Policy
WHERE num_Of_nonClustered = 0
AND Is_Heap = 1
OPEN db_cursor
FETCH NEXT FROM db_cursor INTO @name
WHILE @@FETCH_STATUS = 0
BEGIN
——-Cusror NO 2
DECLARE @name2 NVARCHAR(100)
DECLARE db_cursor2 CURSOR
FOR
SELECT name
FROM sys.columns
WHERE object_id = OBJECT_ID(@name)
AND column_id = 1
OPEN db_cursor2
FETCH NEXT FROM db_cursor2 INTO @name2
WHILE @@FETCH_STATUS = 0
BEGIN
DECLARE @SQL NVARCHAR(MAX)= N’Create Clustered index [IX_’
+ @name + ‘] on [‘ + @name + ‘]
(‘ + @name2
+ ‘ ASC) with (Fillfactor=80,Data_Compression=page)
GO’
PRINT @SQL
FETCH NEXT FROM db_cursor2 INTO @name2
END
CLOSE db_cursor2
DEALLOCATE db_cursor2
—-End of Cursor 2
FETCH NEXT FROM db_cursor INTO @name
END
CLOSE db_cursor
DEALLOCATE db_cursor
GO
DROP TABLE #Table_Policy
———————————————————————————————————————————————–
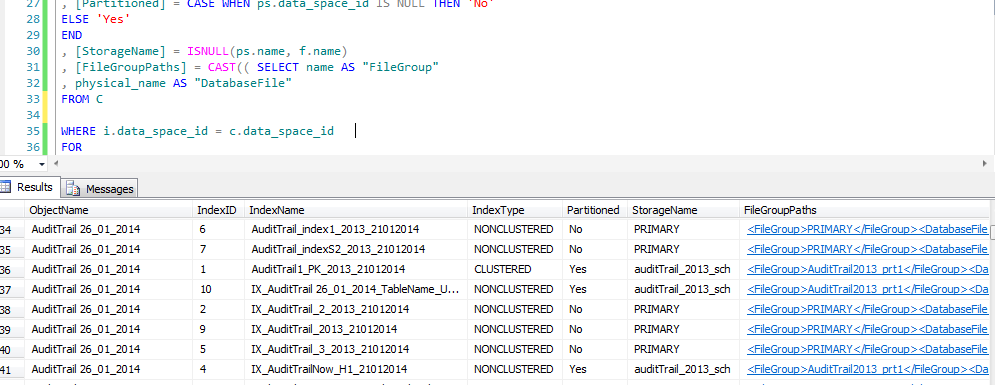
Here i can found 3 tables without any clustered index or Non clustered index

If you check the massage you will find the T-SQL print for the Creating of Clustered index for the three tables.
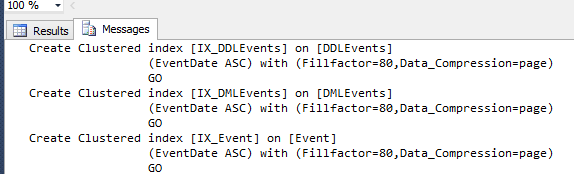
by this way by one single click you can fix all heap tables on your databases
Follow the author:
View all my tips , LinkedIn , Website , Slideshare , ABOUT ME