Query performance is a very important area of SQL server. We always have badly performance queries around.
Query store is the newest tool for tracking and resolving performance problems in SQL server.
In this article, we are going to have a look at some practical uses of SQL server Query store.
What is Query Store?
The query store has been described by Microsoft as a ‘flight data recorder’ for SQL server queries. It tracks the queries run against the database, recording the details of the queries and their plans and their runtime characteristics. Query store is per database feature and runs automatically. Once turned on, nothing further needs to be done to get it to track data. It runs in the background collecting data and storing it for later analysis.
Query store is available in SQL Server 2016 and later, and Azure SQLDB v12 and later. It is available in all editions of SQL server, even in Express edition.
How is Query store different from other tracking options?
We have had query performance tracking for some time though in the form of dynamic management views. Mostly, sys.dm_exec_query_stats and sys.dm_exec_query_plan and tracing tools like SQL server profiler and extended events.
So, what makes Query Store different? Let me start answering that by describing a scenario that I encountered a couple of years ago.
A particular critical system was suddenly performing badly. It had been fine the previous week and there have been no extended events sessions or profiler traces running historically. The admin had restarted the server when the performance problem started, just to make sure it was not something related to a pending reboot.
As such, there was no historical performance data at all and solving the problem of what happened, why the query performance is different this week was extremely difficult.

Query store would have solved the problem of the lack of historical data. Once turned on, query store tracks query performance automatically. The data collected is persisted into the user database and hence -unlike with the DMVs- it is not lost on a server restart.
Since the query store data is persisted into the user database, it is included in the backups of that database as well. This makes it much easier to do a performance analysis in somewhere other than the production server now.

What exactly is a query performance regression?
A dictionary does not help much here. The Oxford dictionary defines regression as returning to an earlier state which is definitely not relevant here.
A performance regression occurs when a query has degraded in performance over time. This degradation may be sudden or it may be gradual. It is probably more common for regression to be sudden. The degradation may be permanent or it may at a later point returned to the previously accepted behavior.
What causes a regression?
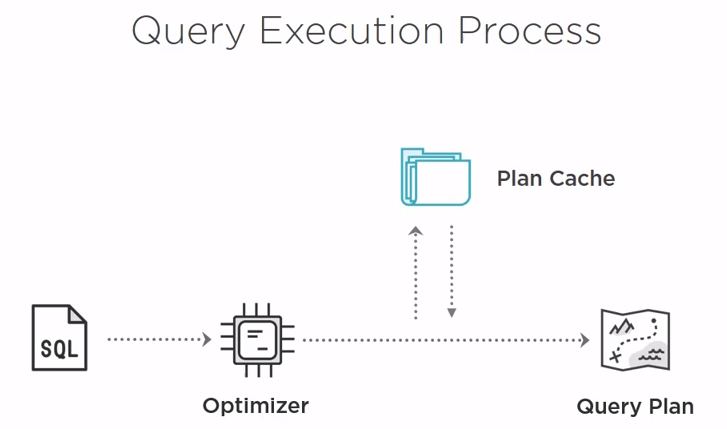
A common cause of a query performance regression is a plan change. Let’s briefly talk about the query optimization on the plan caching process to see why.
TSQL is a declarative language, the query written expresses the desired results, not the process of getting to those results. It is up to SQL server engine to figure out how to get those results and the portion of the engine that figures that out is the query optimizer which takes the query and outputs a query plan. A theoretical operation that the query process that can then execute to obtain the desired results. For anything other than a trivial query there are multiple different plan shapes that can produce the same results but differ in the internal details and differ in how long it will take to execute that plan. In theory, the optimizer will always take a query and produce a good plan –if not the fastest possible plan- is fast enough. However, that is not always the case and it is also perfectly possible for a query to have a plan that is fast for some parameter values and really slow for other parameter values. Then there is plan caching which is another layer of complexity. Optimization is an expensive process so SQL server caches the execution plans. When the query executes again it can fetch the plan from the cache and execute it without the need for the cost of the optimization process.
There are many minor causes the plan changes like:
- Bad parameter sniffing.
- Out of date statistics.
- Bad query patterns.
- Overly-complicated queries.
These all tend to cause temporary performance regression.
Sometimes the regression can be caused by data growth which will be persistent.
Also, code changes or schema changes can cause a performance regression.
Tracking and diagnosing query performance regressions with the query store:
First of all, we should enable query store option using the following statement:
ALTER DATABASE [SQLSHACK_Demo] SET QUERY_STORE = ON;
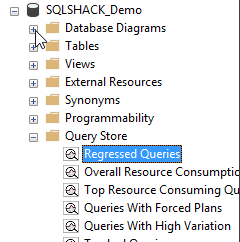
Then whenever you encounter any query performance problems with your application, simply you can open your database in SQL server management studio and expand out the query store folder and then open the regressed query report.
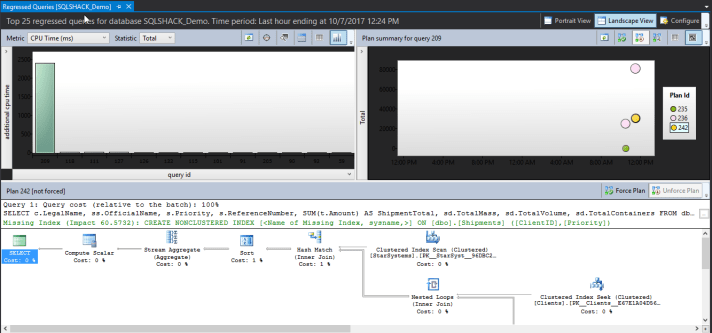
You will see the report with the default configurations which indicates total for the duration but this is not ideal. What we want is to check for regression in CPU time because that eliminates cases of blocking and then indicates the appropriate intervals that you want to investigate in:
You can change these configurations of the data viewed if you clicked on configure button on the top right of the report to get the following page:
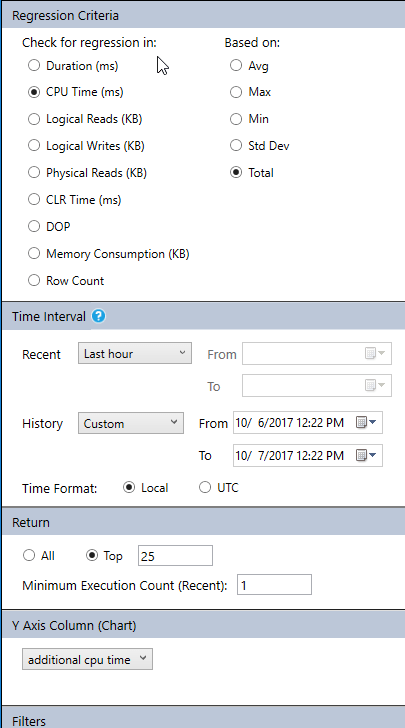
Now, we can see how it behaved over time and we can see that this query has two plans associated with it.
And if we hovered over the bars of the paragraph in the top left corner we can see the query behavior in the recent and historic intervals and we can see how they differ.
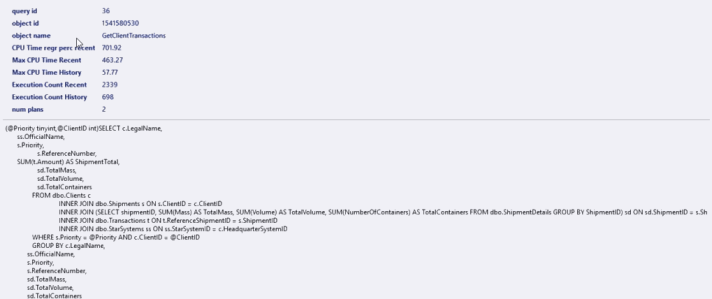
We can also see how many plans the query has on the top right paragraph if we clicked on the query bar and if we clicked on any of the plans shown we can see its graphical display down on the window.
Fortunately, you can select both plans and click on compare plans button to compare them.
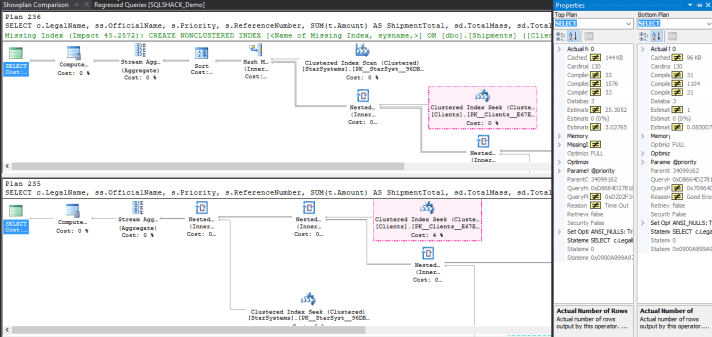
In our case here, we can conclude that we definitely do have a case of a bad parameter sniffing. We have got two plans. One is appropriate for all executions and one that was generated by a ‘’NULL’’ parameter value and is not suitable for the majority of executions for this query. I know that we can fix this later.
But, what if we need to fix this now. Here comes query store to show the easiest way to do this by choosing the fastest plan and click force plan button.
From that point onwards, the query will be executed with the forced plan no matter what parameter values the query is compiled with. So the application now is performing well.
Now we want to do further analysis to identify why this happened and how to prevent it in a long-term without resulting to plan forcing. This is kind of investigation we do not really want to do on a production server. And here also query store introduces the easiest way to do that by just backing up and restoring the production database to our test environment and then have a look at our query store regressed queries report again.
Summary:
Query performance regression can face any DBA every day so you had to know what caused it and how to track that regression over time. This article was to show how much easier query store makes it. I hope this article has been informative for you.
