It can often be bugs and errors in fetching data from the server. This can leave system administrators baffled as all work comes to a standstill. Incomplete or incorrect transaction cause confusion among employees working on the different sections of a database.
One such frequent issue is the SQL Server torn page error. It can be quite a hassle for a non-technical user facing such a situation. There are ways to fix it easily without worrying about any data loss. This post covers all there is to know about this topic. Continue reading to find out more.
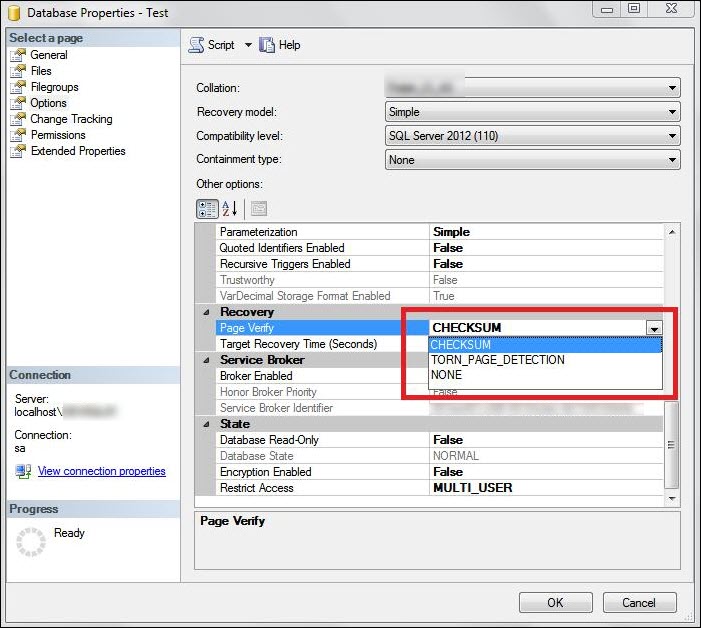
What is the Torn Page in SQL Server?
It is the inability of the server to fetch a particular data during a transaction. It is caused when an Input/Output header tries to access a page that was written incorrectly to the disk. It reports a message saying ‘I/O error (torn page) detected during read’. The reason for this can be primarily contributed to power failure causing partial writes. Other factors include damaged disk or other hardware to which data is being written to. If a torn page is detected by SQL Server, it will sever all connections as the requested data is inaccessible. During the restore process, detecting a torn page sends the database into SUSPECT mode.
Continue reading “SQL Server Torn Page Repair: Without Worrying About Data Loss or Corruption”