Azure Synapse is the new Generation of SQL DW (Azure SQL Data Warehouse), that is launched in the past year In November 2019 the First announced for Azure SQL Synapse was in Microsoft Ignite 2019, With Azure Synapse you can bring together cloud data warehousing and big data analytics into a single service platform, Azure Synapse is massively parallel processing (MPP) Engine. Microsoft Added on it many features, With Azure, Synapse Compute is separate from storage, this means you can scale compute independently for the data in your System (APP), With Azure synapse, you can bring the relational Data and Non-relational data together in one place and easily you can do your query and your analytics on a huge amount of information, Azure Synapse build for a massive parallel query for Analytics not for transaction database, Azure Synapse uses Azure Data Lake Storage Gen2 for more information About Azure Data Lake Gen2 Check this Post, Azure Synapse Support (Apache Spark integration, Power BI, Azure ML), Also you can take a look to this demo with Rohan Kumar this demo is part from Microsoft Ignite 2019 Keynote and you can Follow Rohan Posts from here
Azure Synapse Distribution
Distribution is the basic unit for Storage and processing for parallel queries to Distribute your data in multiple Compute node, and when you run a query on Azure synapse it is divided or splitted into 60 smaller queries that run in parallel, to get your results faster, and you can choose Which pattern you need it to distribute your data and this depends on the usage of this data and the table size

Distributed tables in Azure Synapse
With Azure Synapse we have 3 patterns you can choose between them (Hash, Replicate, Round Robin)
Hash-distributed tables
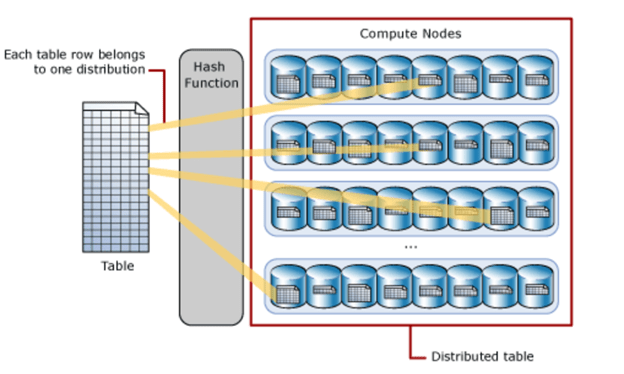
Any table have Rows in a table, with Hash-Tables each of these rows are assigned to Specific compute node using deterministic Hash Function and in the table, there is one column defined as distribution column and this deterministic Hash Function used the values in this column to assign each row to a distribution Compute node. So, this means Rows based on Value and with this mechanism, you can reduce your query execution and get better performance for your queries, Hash table is designed for big data table or tables have frequent OLTP transaction (Update, Delete, insert), So with Hash tables, you can get the Highest query performance for joins and aggregations on large tables. Because when you do a query on Hash tables, Hash Function will direct the query to the exact rows in the specific Compute node.
Replicated Tables
In this type of tables, all your data will be Fully replicated to all Computed nodes that’s why this Replicated tables designed for small tables to get fastest query performance if you design large table as replicated table this mean you required more storage and process to replicated this data. And why it is fast because with a replicated table you don’t need to move your data between computed nodes before Join queries because it is already fully copied on all computed nodes that’s why it is faster with small tables.

Round Robin Tables
When you have staging table used for loading data at this time Round Robin tables is the better choice for you to get the best performance, Round Robin Tables somewhat similar Hash-distributed tables but instead of using Hash Function to distributed your rows into computed nodes, it will distribute the table rows equally or evenly across all distributions but this process it’s completely random, Also Round tables can be used when you have tables that need a fast load speed and they’re a lot of queries running on this table.
Resources
- Hash-distributed tables
- Replicated Tables
- Round-robin distributed tables
- Azure Synapse Analytics
- Azure SQL Data Warehouse VS Azure Synapse
- Azure Synapse Free Sessions
Keep Following
Cloud Tech Website blog survey
IF you found this blog is helpful and sharing useful content please take few second to do rate the website blog from here
